非同期と継続と私
非同期のプログラミングの解説の中にはよく「継続(渡し)」が良く出てきます。継続といえば Scheme の call/cc ですが、やっぱり JSDeferred のサンプルのページにも出てきます。直感的にはあんまり関係ないような気がしますが、関係があるようです。
さらに、非同期と遅延評価の関係も気になります。非同期は「結果が後で来る」感じですが、遅延評価は「必要になるまで結果を計算しない」ということで、後回しにする感じが似ています。
今回、deferred.el を作った後にこれらについて考えてみたところ、なんとなく自分の中で実用的な結論に達したのでまとめてみました。以下、その過程とまとめです。
あらすじ
- 継続渡し(CPS)と非同期
- CPS変換から非同期化
- Deferredで非同期化
- 遅延評価と非同期
- 遅延関数のCPS変換から非同期化
- Deferredで非同期化
- 明示的形式と暗黙的形式
- 継続とDeferred
- 非同期の設計・アーキテクチャ
- 非同期のトピック・話題
記事の中の完全なソースコードやメモは gist に貼ってあります。省略した部分をフォローしたり、実際に動かしてみたい方は参考にしてみてください。
継続渡し形式(CPS)と非同期
まずは継続渡し形式(Continuation Passing Style)と非同期との関係です。結論から書くと、Deferredを使うことで非同期の処理をCPSよりもシンプルに描き直すことが出来ます。
実際にEmacs Lispのプログラムを見ながら確認してみます。題材はみんな大好きフィボナッチです。
元のプログラム(同期的)
まず、フィボナッチの定義から素直に書いたプログラムは以下のようです。
(defun fib (n) (if (<= n 1) n (+ (fib (- n 1)) (fib (- n 2)))))
このプログラムは定義通りでシンプルですが、入力の数が大きくなると、再帰が相当数発生するため非常に遅いです。実際に、このようなプログラムはフィボナッチを大量に計算する目的ではあまり使われません。ここでは、「典型的な遅いプログラム」としてこのプログラムを利用していきます。
これを以下のような関数で計算してバッファに出力します。
※実際に関数を計算して表示する関数は、今後は省略します。ただ、これから示す関数をどのように呼び出して使うのかという重要な情報が入っていますので、興味ある人はチェックしてみてください。
;; 呼び出して表示する関数 (defun callfunc (upper func) (let ((buf (get-buffer-create "*callfunc*"))) (with-current-buffer buf (erase-buffer) (loop for i from 0 upto upper do (insert (format "%4d > %s\n" i (funcall func i))))) (pop-to-buffer buf)))
実行すると以下のように表示されます。
(callfunc 30 'fib) ; 実行 0 > 0 (0.000091 msec) 1 > 1 (0.000127 msec) 2 > 1 (0.000142 msec) 3 > 2 (0.000156 msec) 4 > 3 (0.000173 msec) 5 > 5 (0.000193 msec) 6 > 8 (0.000220 msec) 7 > 13 (0.000256 msec) 8 > 21 (0.000309 msec) 9 > 34 (0.000388 msec) : : 28 > 317811 (1.169075 msec) 29 > 514229 (1.890093 msec) 30 > 832040 (3.053179 msec)
実行している間、Emacsは固まります。最後の計算結果が計算し終わってから、すべての結果が表示されます。
このように、環境が固まらないようにしたり、遅い処理とどう向き合っていくかというのが今回のテーマになります。
継続渡しで同期的に実行
まず正攻法は、遅い処理を細切れにしてバックグラウンドで少しづつ実行する方法です。いわゆるグリーンスレッドです。こうすることで、あたかも裏で平行して実行しているように見せることが出来ます。(もちろんちゃんとしたスレッドが使えればバックグラウンドで処理を走らせることが出来るので楽です。)
Emacs LispやJavaScriptのようにシングルスレッドの環境では、自前で処理を細切れにして非同期に実行する必要があります。処理によっては新しいアルゴリズムを考えて非同期化することも出来ますが、今回は継続渡し変換(CPS変換)をつかって、もとのプログラムの構造を維持したまま機械的に非同期化する方法で進めます。
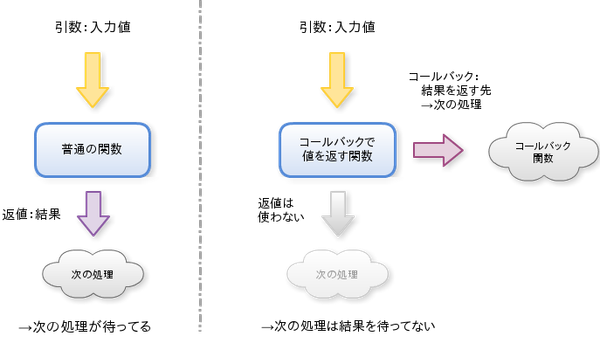
CPS変換とは、簡単に表現すると関数の結果値をコールバックで返すことです。
例えば、以下のような足し算の関数があったときに、
;;返値で結果を返す (defun add (a b) (+ a b)) (message "%s" (add 1 2)) ; => 3 がミニバッファに表示される
CPS変換をして以下のように書き直すことが出来ます。
;;CPS(コールバック)で結果を返す (defun add (a b cc) (funcall cc (+ a b))) (add 1 2 (lambda (result) (message "%s" result))) ; => 3 がミニバッファに表示される
このようにコールバックにしてしまうことで、後続の処理を待たせずに好きなタイミングで結果を返すことが出来るようになります。簡単にイメージを書くと下の図のようです。
もっと詳しいCPS変換については以下の情報が参考になります。
- Continuation-passing style (Wikipedia)
- 何でも継続 (practical-scheme)
- 継続渡し形式(CPS) (Javascriptプログラミング by unkaiさん)
今回のフィボナッチの場合は以下のように変換できます。
(defun fib-cb (n cc) ; 引数にコールバック関数が渡る (if (<= n 1) (funcall cc n) (lexical-let ((n n) (cc cc)) (fib-cb (- n 1) (lambda (x) ; コールバック1つ目 (lexical-let ((x x)) (fib-cb (- n 2) (lambda (y) ; コールバック2つ目 (funcall cc (+ x y)))))))))) ; ここでやっと計算
この時点でもう負けそうなコードです。
実行してみると、もっと大変なことに、スタックオーバーフローで途中で実行が止まります。
(callfuncb 10 'fib-cb) 0 > 0 (0.000076 msec) 1 > 1 (0.000131 msec) 2 > 1 (0.000743 msec) 3 > 2 (0.002135 msec) 4 > 3 (0.004876 msec) 5 > 5 (0.009524 msec) 6 > 8 (0.015993 msec) 7 > 13 (0.024714 msec) ; -> 7まででスタックオーバーフロー
原因は通常の再帰に加えて、コールバック(lambda)のスタックも追加されてEmacs Lispの限界に達しているようです。
継続渡しをそのまま非同期に実行
先ほどのCPS変換したプログラムをよく見ると、コールバック関数は関数内のレキシカルスコープの変数だけしか使っていません。さらに、コールバックの中で計算を行うようにしたので、呼び出した関数(fib-cb)の返値を使って計算しているところがありません。
ということで、関数(fib-cb)の返値は必要ないため、非同期に実行してもかまわないということになります。ということで、ここを機械的に非同期に書き換えてしまいます。
(require 'deferred) ; 非同期の便利ツール (defun fib-cbd (n cc) (if (<= n 1) (deferred:call cc n) ; 非同期化 (lexical-let ((n n) (cc cc)) (deferred:call 'fib-cbd (- n 1) ; 非同期化 (lambda (x) (lexical-let ((x x)) (deferred:call 'fib-cbd (- n 2) ; 非同期化 (lambda (y) (deferred:call cc (+ x y))))))))))
関数呼び出しを deferred:call に書き換えました。これは funcall と同じ形で使えるもので、非同期で関数を呼び出します。(内部では elisp的には run-at-time 、JavaScript的には setTimeout の形で呼び出していることになっています。)
実行してみると以下のようになります。
(callfuncb 14 'fib-cbd) ; -> 計算結果が順次表示される 1 > 1 (0.115368 msec) 2 > 1 (0.478819 msec) 3 > 2 (0.569296 msec) : : 10 > 55 (2.132786 msec) 11 > 89 (2.750348 msec) 12 > 144 (3.555442 msec) 13 > 233 (4.632972 msec) 14 > 377 (6.410187 msec)
計算結果が1行ずつ表示され、さらにはEmacsも(あまり)固まらなくなりました。フィボナッチ関数の非同期化の完成です。
ただ、問題はCPS変換を考えることが難しいということだと思います。また、元のプログラムと比較してみると、もはや跡形もありません。
;; 元の関数 (defun fib (n) (if (<= n 1) n (+ (fib (- n 1)) (fib (- n 2))))) ;; CPS非同期の関数 (defun fib-cbd (n cc) (if (<= n 1) (deferred:call cc n) ; ccって何が入ってくるんだっけ? (lexical-let ((n n) (cc cc)) ; 2行のはずが7行に! (deferred:call 'fib-cbd (- n 1) (lambda (x) (lexical-let ((x x)) (deferred:call 'fib-cbd (- n 2) (lambda (y) (deferred:call cc (+ x y)))))))))) ; カッコもやばい!!!
すごく複雑になってしまったため、CPS変換だけでいっぱいいっぱいです。フィボナッチでこうなってしまったら、これ以上難しいプログラムを非同期化させるのは大変そうです。
Deferredで書き直し
そこでDeferredの登場です。元の関数を deferred.el を使って素直に書いてみると以下のようになります。
(defun dfib (n) (lexical-let* ((n n)) (if (<= n 1) n ; 素直に値を返す (deferred:nextc (deferred:parallel (lambda () (dfib (- n 1))) ; 再帰で呼んで (lambda () (dfib (- n 2)))) ; (lambda (vars) (apply '+ vars)))))) ; 足し算する
CPSよりは怖くない感じです。上から下にすっと読めるようになっています。
値を返したりlambdaを返したりとか、nextcとかparallelとか出てきましたが、CPSの複雑さに比べれば大したことありません。><
実行すると、期待通り以下のようになります。
(callfuncd 14 'dfib) ; 順次答えが出る 0 > 0 (0.242374 msec) 1 > 1 (0.259262 msec) 2 > 1 (0.301911 msec) 3 > 2 (0.336709 msec) : 10 > 55 (2.254487 msec) 11 > 89 (3.747674 msec) 12 > 144 (6.603675 msec) 13 > 233 (12.642975 msec) 14 > 377 (26.109853 msec)
実行時間を見ると、CPS非同期から実行速度が2倍くらい遅くなりましたが、これはdeferred関数の内部で余分に非同期呼び出しを行っているためです。通常の処理の場合は、それほど問題にならないはずだと思います。
ここまでのまとめ
ということで、CPS変換による非同期化と、Deferredによる非同期化を見てみました。
Deferredを使うことで、CPS変換をするよりも楽に非同期化を行えるということが分かりました。
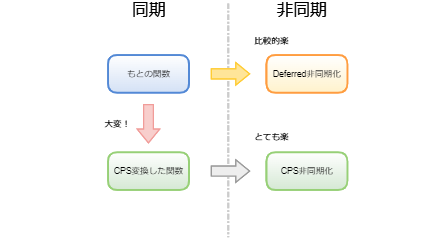
非同期化まとめ
楽になった理由の一つとして、Deferredを使うことによって実行順序がソースコードの記述順序に近くなったということがあげられます。
一般的にマルチスレッドや非同期のプログラムでは、実行の順序がソースコード上バラバラになり、頭の中で処理をつなげなければなりません。これはつまり、ダイクストラ先生が主張したGOTO文によるスパゲティプログラムと同じ状態であるといえます。ダイクストラ先生は「プログラムは建造物に比べて動くという点で設計が難しいのだから、ソースコード(見た目)と実行順序が一致するようなプログラムの書き方をして複雑さを下げるべきだ。」と主張しました。
- Goto statement considered harmful (pdf)
- 『GOTO は有害である』の元論文。
- radiumsoftware.com 上の『GOTO は有害である』への興味深い解説
Deferredを使うことで、ソースコードの見た目と実際の処理を近づけることが出来ます。ということで、Deferredで楽にするためのコツは、見た目の通りに処理が流れるように書くことです。
遅延評価と非同期
次は遅延評価と非同期の関係です。こちらも結論を先に書くと、Deferredを使うことで遅延評価をつくることが出来て、非同期で並列・分散化できる無限のデータ構造が出来るようになる気がしました。
まず、遅延評価・無限リストは役に立つのかという問いに対しては、SICPの3章あたりとかPAIPとかに詳しく書いてあります。無限系(もしくは終わりが特定できないデータ)を扱うという問題は数多く、アーキテクチャパターンの中でも「Pipe and Filters」として定義してあります。具体的な応用例としては、UNIXコマンドラインのパイプや、Javaのストリームやマルチメディアデータを扱うフレームワークなど数多くあります。
delay/forceマクロによる遅延評価
まずは、引数をlambdaで包むことにより評価を遅らせるマクロで遅延評価を書いてみます。
;; delay, force を定義 (defmacro delay (v) (let ((done (gensym)) (val (gensym))) `(lexical-let (,val ,done) (lambda () (unless ,done (setq ,val ,v ,done t)) ,val)))) ;; ↑は以下と大体同じ ;; (defmacro delay (v) ;; `(lambda () ,v)) (defun force (v) (funcall v)) ;; 遅延評価用の car, cdr, cons を定義 (defun stream-car (v) (car v)) (defun stream-cdr (v) (if (null v) nil (force (cdr v)))) (defmacro stream-cons (a b) `(cons ,a (delay ,b)))
まず、stream-consで「次の値」を関数で用意しておきます。必要なときに stream-cdr が呼ばれる訳ですが、その時に関数を実行して「次の値」を用意するというイメージです。これらを使うことで無限リストを定義できます。
それではフィボナッチを遅延評価を使って書いてみます。
(defun fib-gen (a b) ; フィボナッチ無限リスト生成関数 (lexical-let ((a a) (b b)) (stream-cons a (fib-gen b (+ a b))))) (setq fibs (fib-gen 0 1)) ; 初期値を入れて無限リスト生成
非常にシンプルに出来ました。consの中で、後ろの値を再帰呼び出しにしています。consが関数であれば無限ループ(再帰)ですが、マクロによる遅延評価で再帰が止まっています。
実行してみます。
(print-stream 50 fibs) ; 50まで求めてみる 0 > 1 (0.001115 msec) 1 > 1 (0.002118 msec) 2 > 2 (0.003069 msec) 3 > 3 (0.004030 msec) : : 48 > 7778742049 (0.035559 msec) 49 > 12586269025 (0.036105 msec) 50 > 20365011074 (0.036596 msec)
これまでのプログラムに比べて圧倒的に速いです。速い理由は遅延評価にしたからでは無く、今までと違うアルゴリズム(線形ループの形)で計算しているからです。
このフィボナッチの無限リストの形を明示的形式(Explicit Form)と呼ぶそうです。consの中でリストの要素を直接計算しているところが「明示的」なのだと思います。
それでは明示的でないものはどんなものかというと、リストでリストを定義するような形(暗黙的形式 : Implicit Form)というそうです。
まず、 stream-add というリスト同士の演算を定義します。
;; リスト同士の足し算 (defun stream-add (&rest lsts) (apply 'stream-map '+ lsts)) ;; リスト同士の汎用演算 (defun stream-map (proc &rest lsts) (lexical-let ((proc proc)(lsts lsts)) (stream-cons (apply proc (mapcar 'stream-car lsts)) (apply 'stream-map proc (mapcar 'stream-cdr lsts)))))
これを使ってフィボナッチの無限リストを定義すると以下のようになります。
(setq fibs (stream-cons 0 (stream-cons 1 (stream-add fibs ; 自分自身と (stream-cdr fibs))))) ; 自分自身を一つずらしたリスト
Haskellなどのフィボナッチの定義と同じ形式で書けました。
-- Haskell版 fib = 0:1:zipWith (+) fib (tail fib)
実行してみます。
(print-stream 50 fibs) 0 > 1 (0.000191 msec) 1 > 1 (0.001556 msec) 2 > 2 (0.002720 msec) 3 > 3 (0.003751 msec) : : 50 > 20365011074 (0.032877 msec)
これもかなり速く動きました。同期的なプログラムなのですべての結果が出るまでEmacsが固まってしまいますが、気にならない速度です。
ということで、Emacs Lispでの遅延評価の復習でした。次は、この遅延評価を非同期でやってみるという内容です。
継続渡し(callback)による無限リスト
上の遅延評価は同期的な定義でしたので、これまでと同様に結果をコールバックで受け取れるようにCPS変換してみます。cdrの結果をコールバックで返すようにしてみます。
(defun streamcb-car (v) (car v)) (defun streamcb-cdr (v cb) ;; cbに継続でcdrの値が渡ってくる (if v (funcall (cdr v) cb))) (defun streamcb-cons-gen (a cdr-fun) ;; cdr-funには結果をコールバックで返す関数を渡す (cons a cdr-fun))
ちょっとややこしいですが、以下のように使います。
;; 使い方例 : (streamcb-car (streamcb-cons-gen 'x (lambda (cb) (funcall cb 'y)))) => x (streamcb-cdr (streamcb-cons-gen 'x (lambda (cb) (funcall cb 'y))) 'identity) => y
やっぱりこのまま使うのは無理なので、マクロでラップします。
;; consっぽく書けるようにするマクロ (defmacro streamcb-cons (a b) `(streamcb-cons-gen ,a (lambda (cb) (funcall cb ,b) nil)))
このように見た目が普通になります。
;; 使い方例 : (streamcb-car (streamcb-cons 'x 'y)) => x (streamcb-cdr (streamcb-cons 'x 'y) 'identity) => y
これを使ってフィボナッチの無限リストを定義してみます。まずは明示的形式です。
;; 明示的形式 (defun fibcb-gen (a b) (lexical-let ((a a)(b b)) (streamcb-cons a (fibcb-gen b (+ a b))))) (setq stream-fibcb (fibcb-gen 0 1))
簡単にできました。実行してみます。
(print-streamcb 100 stream-fibcb) 0 > 1 (0.000584 msec) 1 > 1 (0.001094 msec) 2 > 2 (0.001539 msec) 3 > 3 (0.002005 msec) : 50 > 20365011074 (0.018180 msec)
普通に速いです。次は暗黙的形式をやってみます。
まず無限リスト同士の演算を定義します。
(defun streamcb-map (proc &rest lsts) (lexical-let ((proc proc)(lsts lsts)) (streamcb-cons (apply proc (mapcar 'streamcb-car lsts)) (apply 'streamcb-map proc (lexical-let (rests) ; 同期実行を仮定 (mapcar (lambda (lst) (streamcb-cdr lst (lambda (v) (push v rests)))) lsts) (nreverse rests)))))) (defun streamcb-add (&rest lsts) (apply 'streamcb-map '+ lsts))
一カ所同期的実行を仮定したところがあります。
次はフィボナッチを定義してみます。
;; 暗黙的形式 (setq fibs (streamcb-cons 0 (streamcb-cons 1 (lexical-let (ret) ; ここでも同期実行を仮定 (streamcb-cdr fibs (lambda (second-fibs) (lexical-let ((second-fibs second-fibs)) (setq ret (streamcb-add fibs second-fibs))))) ret))))
ここでも同期的実行を仮定したところがあります。そもそも見づらいです。
ここもマクロ(streamcb-acdr)で本質のみ取り出すと以下のようです。
;; 暗黙的形式 (setq fibs (streamcb-cons 0 (streamcb-cons 1 (streamcb-acdr fibs ;; 自分自身のcdrを参照 (streamcb-add fibs next))))) ;; 自分自身を参照
と、かなり見やすくなりました。実行してみるとかなり遅いです。
(print-streamcb 10 fibs) ; 遅いので控えめ 0 > 1 (0.000205 msec) 1 > 1 (0.002344 msec) 2 > 2 (0.005933 msec) 3 > 3 (0.012777 msec) : 9 > 55 (0.286495 msec) 10 > 89 (0.490727 msec)
主な遅い原因は、先ほどのdelayとは違って遅延評価にキャッシュの仕組みがないからです。あとは処理が複雑になったということもあります。
非同期の連鎖による無限リスト
上でCPS変換を行ったので非同期にしてみます。やり方は先ほど同様、cdr内部の関数呼び出しをdeferred:callで非同期呼び出しにします。
(defalias 'streamcba-car 'streamcb-car) ; 前と同じ (defalias 'streamcba-cons 'streamcb-cons) ; 前と同じ (defun streamcba-cdr (v cb) ;; cbの関数にcdrの値が渡ってくる ;; deferred:callで非同期実行 (if v (deferred:call (cdr v) cb)))
次にフィボナッチの無限リストを定義して実行してみます。
;; 明示的形式 (defun fibcba-gen (a b) (lexical-let ((a a)(b b)) (streamcba-cons a (fibcba-gen b (+ a b))))) (setq stream-fibcba (fibcba-gen 0 1)) ; 無限リスト生成 (print-streamcba 20 stream-fibcba) ; 実行 1 > 0 (0.004411 msec) 2 > 1 (0.013077 msec) 3 > 1 (0.027801 msec) 4 > 2 (0.038971 msec) 5 > 3 (0.046074 msec) : 18 > 1597 (0.120933 msec) 19 > 2584 (0.126033 msec)
このように結果が出ました。速度も悪くありません。
さて、この次は暗黙的形式を行うはずなのですが、さきほど同期的実行を仮定したところを、非同期待ち合わせなどを駆使してうまく書き直さなければなりません。かなり現実的でないコードになりそうなので、ここはあきらめます!!!
Deferredで無限リスト
それでは、Deferredで無限リストを作ってみます。先ほどは cdr をCPS変換しましたので、同様に cdr をDeferred化します。
(defun dstream-car (v) (car v)) (defun dstream-cdr (v) ;; deferredでcdrの値が渡ってくる (if v (deferred:call (cdr v)))) (defun dstream-cons-gen (a cb) ;; cbにはコールバックでcdrの内容を返す関数 (cons a cb))
以下のように使います。
(defun dmessage (d) ; 結果表示用 (deferred:nextc d (lambda (x) (message ">>> %s" x)))) (dstream-car (dstream-cons-gen 'x (lambda () 'y))) => x (dmessage (dstream-cdr (dstream-cons-gen 'x (lambda () 'y)))) => y
これも使いやすいようにマクロにしておきます。
(defmacro dstream-cons (a b) `(dstream-cons-gen ,a (lambda () ,b))) (dstream-car (dstream-cons 'x 'y)) => x (dmessage (dstream-cdr (dstream-cons 'x 'y))) => y
これらを使って明示的形式でフィボナッチの無限リストを定義してみます。
;; 明示的形式 (defun dfib-gen (a b) (lexical-let ((a a)(b b)) (dstream-cons a (dfib-gen b (+ a b))))) (setq dstream-fib (dfib-gen 0 1)) ; 無限リスト生成 (print-dstream 20 dstream-fib) ; 実行 1 > 0 (0.140674 msec) 2 > 1 (0.175473 msec) 3 > 1 (0.183618 msec) : 19 > 4181 (0.414042 msec) 20 > 6765 (0.421383 msec)
ここまでは簡単に出来ました。次はCPS変換の非同期化でできなかった暗黙的定義です。
delayの遅延評価と同様に、リスト同士の演算を定義します。
(defun dstream-map (proc &rest lsts) (lexical-let ((proc proc)(lsts lsts)) (dstream-cons-gen (apply proc (mapcar 'dstream-car lsts)) (lambda () (deferred:$ (deferred:parallel (loop for lst in lsts ;ここでcdrを要求して回る処理 collect (lexical-let ((lst lst)) (lambda () (dstream-cdr lst))))) (deferred:nextc it ; すべてのリストのcdrを待ち合わせて次へ (lambda (results) (if results (apply 'dstream-map proc results))))))))) (defun dstream-add (&rest lsts) (apply 'dstream-map '+ lsts))
ちゃんと非同期待ち合わせも含めて実装できました。
それではフィボナッチを定義してみます。
;; 暗黙的形式 (setq dfibs (dstream-cons 0 (dstream-cons 1 (deferred:$ (dstream-cdr dfibs) (deferred:nextc it (lambda (next) (dstream-add dfibs next)))))))
本質でないところをマクロ(dstream-acdr)でくくると以下のようになります。
;; 暗黙的形式 (setq dfibs (dstream-cons 0 (dstream-cons 1 (dstream-acdr dfibs (dstream-add dfibs next))))) (print-dstream 13 fibs) ; 実行 1 > 0 (0.007839 msec) 2 > 1 (0.032135 msec) 3 > 1 (0.055160 msec) : 11 > 55 (2.845847 msec) 12 > 89 (5.046634 msec) 13 > 144 (9.097059 msec)
かなり遅いですが、何とか実行できました。
これまでの3つの書き方(Delay、CPS同期、Deferred)での、フィボナッチの無限リスト定義を比べてみます。
(setq fibs ; delayを使った定義 (stream-cons 0 (stream-cons 1 (stream-add fibs ; ← (stream-cdr fibs))))) ; ここの順番が違うぐらい (setq fibscb ; CPS同期の定義 (streamcb-cons 0 (streamcb-cons 1 (streamcb-acdr fibs (streamcb-add fibs next))))) (setq dfibs ; deferredを使った定義 (dstream-cons 0 (dstream-cons 1 (dstream-acdr dfibs (dstream-add dfibs next)))))
フィボナッチの定義自体にはほとんど差がありません。実際にはこの無限リストを扱う方のプログラムの差もあるのですが、コードを見ると分かりますが、それほど大きくはありません。
Deferredによる非同期化を行うことで、オリジナルのdelay/forceの遅延評価プログラムとほとんど変わらないレベルで、非同期な無限リストが扱えることが分かりました。
これまでの試行錯誤の結果をまとめると下の図のようになります。
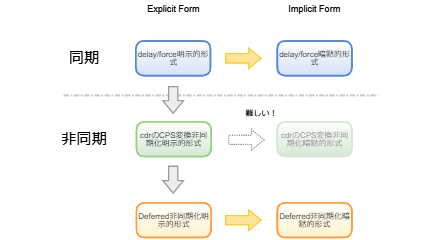
遅延評価の非同期化まとめ
明示的形式と暗黙的形式の差
先ほどの例の中で、無限リストの暗黙的形式のCPS変換による非同期化は困難なので実装をあきらめました。
この困難の原因を生んでいる、明示的形式と暗黙的形式の間にあるものを考察してみます。
明示的形式も暗黙的形式も自分自身のリストから値を取ってきて、非同期で計算して次の値を作り出すという機能については同じです。しかしながら、「どこからどうやってデータを取ってくるか」という点において、大きな違いがあります。図にまとめてみました。
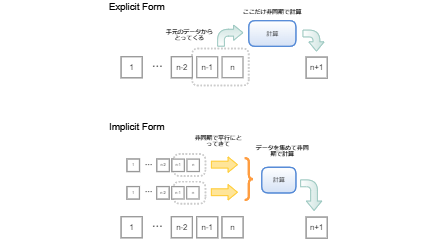
明示的形式と暗黙的形式の計算の動き
明示的形式の方法は、コードで示されているとおり、すでに計算に必要な値がスコープの中にあります。ですので、実際の計算はスコープの中の値を取ってきてそのまま計算するだけです。非同期は1回だけです。
一方で、暗黙的形式では、計算に必要なデータは「リスト」として渡されています。これらの渡されたリストから非同期で値を取ってきて、両方のデータがそろったところで、非同期で計算して値を返します。このため、複数の非同期の結果をまとめる「非同期待ち合わせ」が必要になります。さらに、非同期が連続するため、非同期の処理同士をつなげるコードを書かなければなりません。一般的にこれらをベタに正しく書くことは非常に面倒なため、暗黙的形式のCPS変換による非同期化はあきらめました。
ところで、暗黙的形式の計算のなかで、実際に渡されるリストは自分自身なのですが、別に全然別のリストであってもいいわけです。また、演算は2つまでというわけではなく、汎用的に定義されています。つまり、「処理に時間かかる外部のデータ(リスト)」から「非同期(平行に)でたくさんのデータを集めて」きて、さらに非同期で計算を行って、値を返すことが出来るわけです。
これはどこかで見たような分散処理です。並列とか分散を扱える言語環境の場合、処理系、または付属のライブラリが自動的に順序をつけて並列化したり、分散処理してくれます。Emacs Lispでも、通信さえうまくできれば、Deferredを使うことで楽に並列分散環境を再現することができそうです。
以上、遅延評価をDeferredで非同期化して、さらに暗黙的形式を定義することで、分散処理可能な無限のデータ構造を作れそうなところまできました。この流れを図にしてみました。(ちなみに、矢印は進化の流れではなくて、考えていった道筋というか連想のつながりのようなものです。)
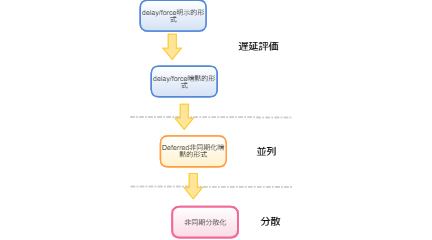
遅延評価から並列分散へ
deferredで継続で定義
最後は、Deferredのもう一つの側面の「継続」をすこし考えてみます。
JSDeferredは結果の待ち合わせをしない代わりに、Deferredオブジェクトを再利用できます。これはつまり、同じ処理を何度も実行できるということになります。また、Deferredのタスク定義時のスコープをクロージャーで保持出来ることから、call/ccのような動きが出来ます。実際に、JSDeferredのサンプルにはcall/cc的な仕組みを使ったamb(非決定性計算)の例があります。
deferred.elも、待ち合わせの結果が捨てられるという以外には、Deferredオブジェクトを使い回すことについては特に問題ありません。
ここではコルーチン的なものを使ってジェネレーターを作ってみます。(co-routine 自身の実装はgistのコードを参照してみてください。)
;; ジェネレーター定義 (defun fib-generator (cc) (lexical-let* ((a 0) (b 1) (n 0)) (co-routine cc (yield a) (yield b) (while t (setq n (+ a b)) (setq a b b n) (yield n))))) (setq fibgen ; フィボナッチ数列ジェネレーター生成 (fib-generator (lambda (x) (message ">> %s" x)))) (funcall fibgen) ; => 実行するたびにフィボナッチ数が一つずつ表示される
ジェネレーターの yield の式のところで一旦処理が止まります。再度ジェネレーターを実行すると、yieldで止まっていた処理が再開されます。(ように見えます)
あまりちゃんとした実装ではありませんが、このようにフィボナッチの数列を無限ループのように書くことが出来ます。
これまでの実装は、どちらかというと「データを求められた分だけ作り出す」という動きでしたが、こちらのジェネレーターは処理の中から外の世界に積極的にデータを送り出している感じになっています。
この「データを送り出す」という動きを「メッセージ」に変えてみると、やっぱりどこかで見たアクターモデルです。実際には、もう少しうまくメッセージ送受信の環境を整える必要がありますが、たくさんのアクターのような独立したスレッドのようなコルーチン処理を作って、メッセージで非同期通信させることは十分可能です。
ということで、Deferredの継続の話からアクターモデルまでつなげてみました。
非同期の設計・アーキテクチャいろいろ
今回は「時間のかかる計算処理」の非同期化を行ってみましたが、ローカルアプリの時間のかかる処理はやはりディスクやネットワークとのIOです。これらは非同期のプリミティブなAPIがあったりすると思いますので、非同期化は非常にやりやすいと思います。うまく非同期化することによって、システムの負荷を下げたり体感速度を上げることが出来ます。非同期を上手に制御して、サクサク動く気持ちいいアプリを作っていけるのではないかと思います。
さて、これまで述べたCPS変換やDeferredによる非同期の他にも、そもそも設計・アーキテクチャを変えてしまって非同期にする方法があります。
特にサーバー側ではAjaxなどの接続方法の変化からC10K問題が課題になり、スレッドやプロセスを増やさずに大量の処理をさばく手法としてイベントベースの非同期フレームワークが注目されています。
大量の接続の問題だけでなく、巨大データの扱いも非同期が中心になります。分散処理だとMapReduce、またオープンソースのHadoopなどが有名です。ログや大量のバッチデータなどをうまく分散して効率的に処理する手法です。さらに昔にはJavaSpaceとかもあったような気がします。
このように、非同期は「大量のアクセス」「大量のデータ」「分散」さらには「ユーザーインタフェース」を扱うのに必須の技術だと言えます。逆に言うと、非同期こそプロの仕事と言えるのかもしれません。
非同期トピック、実装いろいろ
最後に、おもしろそうな非同期のトピック、実装をいくつかあげてみます。
YAPCなどを見てると、Perl 周辺はサーバーの非同期化が進んでいるようで、とても楽しそうです。
- YAPC::Asia 2009 / Asynchronous Programming for (A)synchronous Communication
- コルーチンとウェブアプリケーション・スケーラビリティ - subtech
Perl界隈の飽くなき姿勢は大変刺激になります。今年の動画はまだ見れてません。
AnyEventについてはこちらを見てみました。
我らがMicrosoftも負けてません。.NET4からDeferredっぽいAPIが来たようです。
WaitAny, WaitAll がいい感じです。Rxというライブラリもおもしろいようです。
非同期タスクなのにSQLみたいな書き方になっていて、すごく楽しそうです。「Rx始まりすぎてる。今更言うのもアレですが、これは確実にヤバい。ビッグウェーブはもう既に来てる。乗り遅れてもいいんで乗ろう!」だそうです。
福岡のスタートアップでも非同期で重い処理をうまくこなしているようです。
今週は「実践クラウド技術セミナー福岡」で、まさにHadoopやScalaの話があったようです。
業務システムなどで非同期と来ると、メッセージングシステムに話が飛んだりします。
- メッセージキュー - Wikipedia
- AP4R,Rubyで非同期メッセージング:第1回 軽量さと堅牢さを兼ね備えたメッセージング|gihyo.jp
- Q4M - a Message Queue for MySQL
ビジネス系だとIBMのMQをよく使ったりするみたいですが、あまりうちの近所では見たことがありません。よくあるSIerさんと通信をすると、通信をTCPソケットで手作りしたり、Windows共有フォルダにファイルを置く形の非同期メッセージングがよく見られます。例によって、いろいろ独自仕様だったりするのですが、下手にミドルウエア(や寿命の短いオープンソースの実装)に依存するよりはその道何十年の社内ライブラリの方が寿命が長くていいのかもしれません。
ただ、良くあるのが「UIの操作と直結して同期通信で再送無し」という設計(または仕様)で、さすがにそれはいかがなものかとも思うわけです。でも非同期メッセージングとずさんな業務設計が絡み合って混乱したり、餌を配給するようなメッセージが下手にキューされて意図せず明日届いてひよこが死ぬよりは、UIに通信失敗が出てきて「あ、それなら電話で」とか「じゃあ、明日システムが直ってから操作し直します」となる牧歌的業務(良く言えばシステム障害に対するリスク対応が出来ている)というのはすばらしいなあとも思うわけです。
まだ途中ですが、最近この本を読んでいます。いろいろなプログラミングのパラダイムを、言語の実装を通して説明していて、言語の成長とはこういうことかということが分かっておもしろいです。特に「並列」についての説明がずっと続いていて、いろいろなアプローチがあることが勉強になるだけでなく、人はずっと並列化のことばかり考えていたのだなあと思いました。
")
コンピュータプログラミングの概念・技法・モデル (IT Architects' Archiveクラシックモダン・コンピューティング)
- 作者: セイフ・ハリディ,ピーター・ヴァン・ロイ,Peter Van-Roy,Seif Haridi,羽永洋
- 出版社/メーカー: 翔泳社
- 発売日: 2007/11/08
- メディア: 大型本
- 購入: 9人 クリック: 304回
- この商品を含むブログ (64件) を見る
まとまりのない文章ですみません。
(2010/10/24 プログラムの間違いなどを修正)